|
|
SØØn |
|
Newsletter 15 del 13 aprile 2024
|
|
|
| |
|
|
|
Uno po' di quello che vuoi sapere su IA e informazione!
|
|
|
| |
|
SØØn vuol essere un riepilogo settimanale di alcune delle numerose novità che evolvono continuamente il mondo dell'Intelligenza Artificiale. Non è possibile darne un resoconto completo o esaustivo, ci vorrebbero decine di pagine. Scegliamo quelle che possono riguardare, direttamente o indirettamente, il mondo dell'informazione e del giornalismo. |
| |
|
Un report su GenAI nel giornalismo che dice le cose come sono |
| |
|
Associated Press (AP) ha realizzato un report per valutare l’impatto dell’intelligenza artificiale generativa nel settore dell’informazione dal significativo titolo: “L’intelligenza artificiale generativa nel giornalismo: L’evoluzione del lavoro giornalistico e dell’etica in un ecosistema informativo generativo”.
E perché noi scriviamo "Un report che dice le cose come sono"?
Molto semplicemente perché, nell'esperienza continua di analisi e raccolta di informazioni sul giornalismo e su giornalismo e intelligenza artificiale nelle redazioni, abbiamo riscontrato una certa reticenza a "svelare" l'uso di questi strumenti , soprattutto in relazione a quelli generativi laddove, probabilmente, vi è ancora una diffusa percezione della scarsa qualità dei contenuti prodotti con questi strumenti nel giudizio dei lettori.
Dal report appare invece evidente che l'uso di questi strumenti è una realtà ormai consolidata semmai vi è molta attenzione a collocarli professionalmente ed eticamente in una posizione che sia sempre subalterna al lavoro del professionista.
Il report presenta i risultati di un sondaggio condotto su 292 professionisti dell’informazione tra il 4 e il 22 dicembre 2023 distribuiti in gran parte in Nord America ed Europa ma con rappresentanze anche di altri continenti, focalizzandosi sull’utilizzo attuale e futuro dell’IA, nonché sulle questioni etiche e pratiche correlate. L’81,4% degli intervistati ha dichiarato di essere a conoscenza dell’IA generativa e il 73,8% ha indicato che loro o la propria organizzazione avevano già utilizzato l’intelligenza artificiale generativa in qualche modo. Ma forse l’elemento più interessante riguarda la qualità del campione: il numero medio di anni di lavoro nel settore dell’informazione da parte degli intervistati è stato di 18 anni, ovvero come alcuni dei membri più esperti della professione stanno reagendo alla tecnologia.
Nello studio si osserva come, dopo l’introduzione di ChatGPT da parte di OpenAI alla fine del 2022, altre grandi aziende tecnologiche hanno sviluppato rapidamente i propri modelli di intelligenza artificiale generativa, come Bard e poi Gemini di Google, Claude di Anthropic, Copilot di Microsoft e offerte open source come LLaMA di Meta e la disponibilità di questi strumenti ha portato a un’integrazione accelerata dell’IA generativa in vari prodotti e servizi dell’ecosistema informativo, offrendo nuove opportunità di produttività e innovazione, ma anche sollevando preoccupazioni riguardanti l’accuratezza e la veridicità delle informazioni.
Nel corso del 2023, l’industria dell’informazione ha cercato di comprendere le implicazioni di questa tecnologia per la raccolta, la produzione e la distribuzione delle notizie, nonché per i modelli di business e la proprietà intellettuale.
L’uso dell’intelligenza artificiale generativa ha inevitabilmente modificato la struttura e l’organizzazione del lavoro nell’industria dell’informazione, generando nuovi ruoli e richiedendo linee guida etiche e formazione per un utilizzo responsabile della tecnologia.
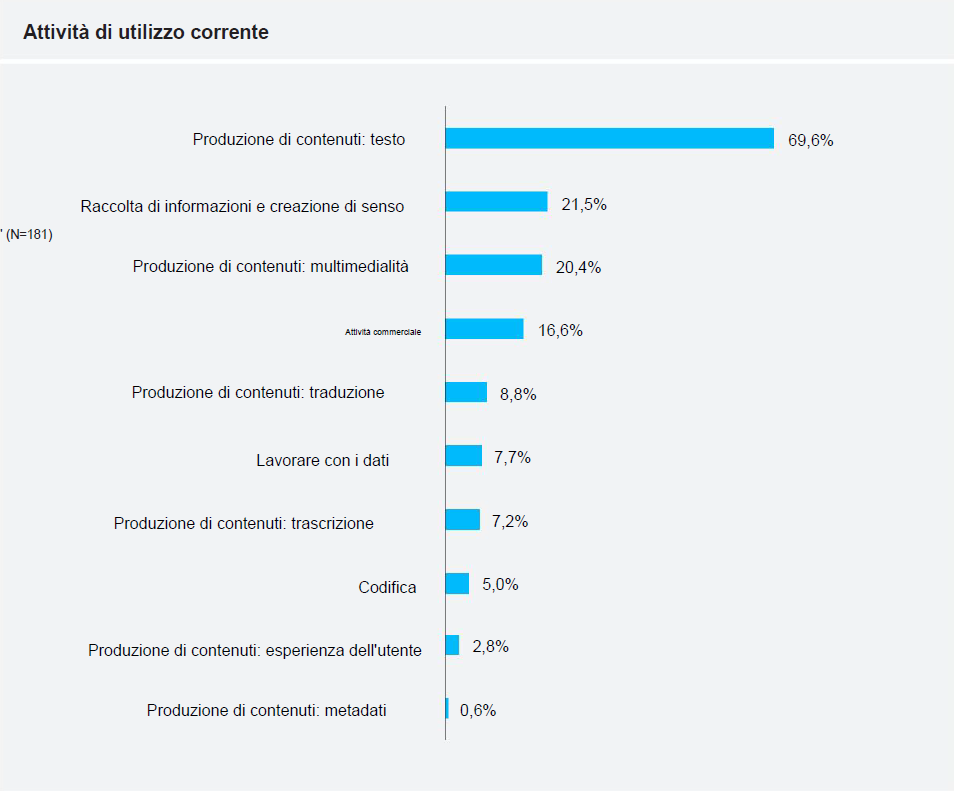
Il report dell’AP ha rilevato le modalità di implementazione dell’IA generativa nel lavoro giornalistico, con gl’intervistati che hanno indicato l’uso della tecnologia per compiti specifici.
La produzione di contenuti (come evidenziato nel grafico sottostante) è risultata essere l’uso predominante, comprendente la generazione, modifica e trasformazione di testi e formati multimediali. L’IA è stata impiegata per generare titoli di notizie, post sui social media, newsletter, nonché per modificare e riassumere articoli, e creare contenuti multimediali come illustrazioni, video e audio. Altri utilizzi includono traduzione, trascrizione assistita, creazione di chatbot e metadati.
Oltre alla produzione di contenuti, l’IA generativa è stata utilizzata per la raccolta di informazioni e la creazione di senso, includendo scoperta di notizie, ricerca e ideazione, oltre a compiti tecnici come codifica e lavoro con i dati e per scopi operativi aziendali interni come la creazione di presentazioni e la stesura di e-mail di marketing. |
| |
|
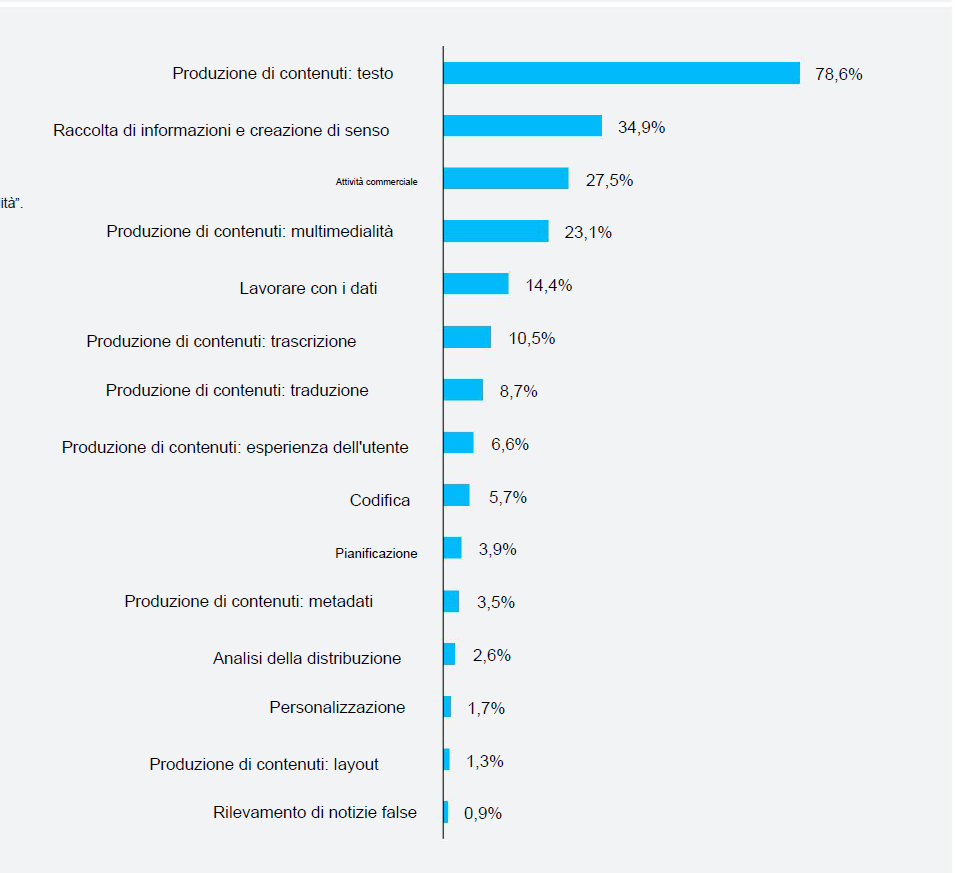
Dalle risposte emerge però un crescente interesse nell’adozione dell’IA generativa per migliorare altri aspetti del lavoro giornalistico: agli intervistati è stato chiesto quali altre attività vorrebbero idealmente svolgere utilizzando l’intelligenza artificiale generativa nel loro lavoro giornalistico, oltre quelle già menzionate, sono emersi altri ambiti come la pianificazione, l’analisi della distribuzione, la personalizzazione, il layout e il rilevamento di notizie false.
Nel contesto della pianificazione, gli intervistati ambiscono a utilizzare l’IA per ottimizzare i flussi di lavoro giornalieri e i piani relativi al ciclo delle notizie. La personalizzazione si concentra sulla creazione di contenuti su misura per i vari settori mentre il rilevamento delle notizie false mira a identificare e contrastare la disinformazione. L’analisi della distribuzione implica l’esame dei dati sull’engagement degli utenti. |
| |
|
Gli intervistati hanno anche espresso un interesse nell’utilizzo dell’IA per supportare l’analisi e la ricerca dei dati, ridurre le attività ripetitive, migliorare l’editing e stimolare la creatività attraverso il brainstorming.
Dai sondaggi raccolti sono stati inoltre rilevati gli aspetti positivi e negativi dell’utilizzo degli strumenti di IA. Da un lato, evidenziano il risparmio di tempo: molti intervistati ritengono che il tempo risparmiato sia un’opportunità per reinvestirlo in altre attività e sottolineano il valore aggiunto che l’IA può portare al processo creativo.
Dall’altro, vengono sottolineati problemi di qualità come mancata accuratezza e affidabilità dei contenuti generati, come la poca pertinenza dei titoli o del testo prodotto dai modelli linguistici di grandi dimensioni.
Gli intervistati individuano anche la creazione di nuovi ruoli all’interno delle redazioni orientati alla ricerca di innovazioni e al monitoraggio dei rapidi cambiamenti nel campo dell’IA.
Nel report inoltre vengono esplorate anche le sfide e le preoccupazioni etiche legate allo sviluppo di pratiche responsabili nel settore dell’IA.
Le preoccupazioni più diffuse riguardano la possibilità di informazioni imprecise e false prodotte dall’IA, insieme alla trasparenza nell’utilizzo di tali tecnologie; inoltre, la riduzione della qualità delle notizie “sintetiche” viene percepita dai lettori, causando una minore rilevanza dell’impatto del giornalismo sulle persone. Altre preoccupazioni riguardano il rischio di perdita di posti di lavoro e la possibilità di plagio delle opere visto che queste vengono utilizzate per l’addestramento dei modelli.
Proprio per questo viene sottolineata la necessità di scoraggiare specifici utilizzi dell’IA generativa nel giornalismo, come la generazione completa di contenuti tramite IA dovrebbe essere vietata, poiché i modelli attuali non sono ancora affidabili per questo compito e potrebbero generare contenuti fuorvianti o ingannevoli, oppure il divieto di utilizzare l’IA generativa per la creazione di domande per interviste e stili artistici.
Questi divieti proposti riflettono la crescente convinzione che ci siano utilizzi dell’IA generativa nel giornalismo che sono moralmente inaccettabili.
Possiamo dire che in generale emerge uno sforzo collettivo all’interno delle redazioni per sostenere gli standard giornalistici, contrastare la disinformazione e mantenere il ruolo del giudizio umano in primo piano nella produzione di notizie.
Gli intervistati sottolineano l’importanza di definire linee guida etiche, regolamenti e controlli di qualità per affrontare tali questioni; molti intervistati mostrano familiarità con linee guida esistenti fornite da organi di stampa come The Guardian, NPR, BBC e AP, ma dai risultati del sondaggio, emerge la necessità di linee guida più concrete e adattabili ai rapidi sviluppi nell’intelligenza artificiale generativa con delineazioni chiare dei casi d’uso consentiti o vietati e l’inclusione di informazioni specifiche sulle applicazioni di intelligenza artificiale generativa che dovrebbero essere divulgati al pubblico. |
| |
|
I dati rubati dalle IA: l'inchiesta del New York Times |
| |
|
Il New York Times, impegnato in una causa che farà la storia di questa problematica per violazione del diritto d’autore da parte di Microsoft ed OpenAI che avrebbero addestrato i propri modelli di IA con miliardi di dati “rubati” al giornale, ha lasciato quasi completamente fuori dal suo paywall e, quindi, accessibile a tutti, un’inchiesta in stile “New York Times” e quindi completa di dati tecnici, pareri scientifici e molte fonti interne alle aziende, dalla quale si evincono in primo luogo le modalità sostanzialmente illecite con cui le aziende di IA si appropriano dei dati presenti in rete.
—
In un mondo dove l’intelligenza artificiale sta definendo i confini dell’innovazione tecnologica, le aziende leader del settore si stanno impegnando in una ricerca incessante di dati digitali, vitali per l’evoluzione delle loro tecnologie. Giganti come OpenAI, Google e Meta sono al centro di un dibattito acceso, poiché le loro strategie di acquisizione dati sollevano questioni legali e etiche, come emerge da un’indagine approfondita condotta dal New York Times dal titolo “Come i giganti della tecnologia smussano gli angoli per raccogliere i dati per l’A.I.” e dal sottotitolo ancora più esplicativo “OpenAI, Google e Meta hanno ignorato le politiche aziendali, alterato le proprie regole e discusso di aggirare le leggi sul copyright mentre cercavano informazioni online per addestrare i loro nuovi sistemi di intelligenza artificiale.”
Il NYT ha svolto questa indagine basandosi su pareri di scienziati, dati noti e pubblici, e una grande quantità di fonti interne alle aziende che restano, per ovvi motivi, anonime.
L’elemento centrale che emerge dall’analisi rappresenta forse la problematica più grande per tutti i sistemi di intelligenza artificiale: la carenza di dati per addestrare i modelli; carenza dovuta da un lato, alla effettiva voracità di questi sistemi i cui progressi sono direttamente collegati alla quantità di dati acquisiti in fase di addestramento, come dimostra la ricerca di Jared Kaplan della Johns Hopkins University, pubblicata nel gennaio 2020 che ha fornito un sostegno teorico a queste iniziative pratiche, suggerendo una correlazione diretta tra la quantità di dati di addestramento e l’efficacia dei modelli linguistici.
Kaplan ha illustrato come i modelli di IA, simili agli studenti che apprendono da un maggior numero di libri, migliorano la loro precisione e capacità analitica con l’aumentare dei dati a loro disposizione.
L’articolo di Kaplan ha fornito una prospettiva innovativa, mostrando che queste “leggi di scala” nell’IA hanno una precisione paragonabile a quelle osservate in campi come l’astronomia o la fisica, un confronto che ha sorpreso molti nel settore. Questa rivelazione ha portato a un nuovo mantra nell’IA: “La scala è tutto ciò di cui hai bisogno”.
L’altro limite alla possibilità di acquisire i dati per l’addestramento dei modelli viene, come ben evidenziato nell’articolo del Times, dall’insieme di norme e restrizioni varie che vanno dal diritto d’autore alla privacy e che pongono ostacoli che però non sembrerebbero aver fermato le grandi aziende protagoniste di questa corsa sfrenata a divorare tutto.
Nel novembre 2020, OpenAI ha lanciato GPT-3, un modello formatosi su una quantità di dati senza precedenti nella storia dell’intelligenza artificiale: 300 miliardi di token. Questo progresso ha permesso a GPT-3 di eseguire compiti con una precisione eccezionale, creando post di blog, poesie e perfino programmando software.
Nello sviluppo del suo modello di punta, GPT-4, OpenAI si è confrontata con la carenza di testi in inglese di alta qualità, un ostacolo significativo. Per superare questa barriera, secondo fonti interne ad OpenAI, i ricercatori avrebbero utilizzato Whisper, un avanzato strumento di riconoscimento vocale capace di trasformare l’audio in testo, per convertire i video di YouTube in testo, nonostante le preoccupazioni interne relative alla potenziale violazione delle direttive della piattaforma.
Questa non è l’unica mossa audace nel settore: Meta ha contemplato l’acquisizione dell’editore Simon & Schuster, un piano che avrebbe potuto garantirle un flusso costante di contenuti letterari di qualità. Tra le strategie valutate da Meta ci sono la negoziazione di licenze e l’acquisizione di editori per accedere a un maggiore volume di contenuti.
Google, d’altra parte, ha espanso i suoi orizzonti aggiornando i termini di servizio per integrare dati da Google Docs e Google Maps, una manovra strategica per arricchire le sue risorse informative per l’AI. |
| |
|
L’urgenza di acquisire dati è palpabile, con previsioni che indicano una possibile scarsità di dati di alta qualità disponibili online entro il 2026. Questa situazione spinge le aziende a un consumo di dati senza precedenti, spesso al limite delle regolamentazioni vigenti. In questo contesto frenetico, figure come Sy Damle di Andreessen Horowitz evidenziano che l’addestramento su vasti insiemi di dati senza vincoli di licenza potrebbe essere l’unica via percorribile per mantenere il passo dell’innovazione.
DeepMind, affiliato a Google, ha seguito pedissequamente queste indicazioni, spingendo i limiti con il modello Chinchilla, addestrato su 1,4 trilioni di token. Ma questa cifra è stata presto superata da altre innovazioni, come il modello Skywork cinese, addestrato su 3,2 trilioni di token, e PaLM 2 di Google, che ha sfiorato i 3,6 trilioni di token.
Tuttavia, questa frenetica corsa ai dati non è priva di complicazioni. L’uso massiccio di opere creative per addestrare questi modelli ha sollevato questioni legali, come evidenziato dalle azioni legali intraprese dal Times contro OpenAI e Microsoft per l’utilizzo di contenuti senza permesso. Questa situazione ha spinto oltre 10.000 entità a esprimere, negli Stati Uniti, le loro preoccupazioni al Copyright Office, avviando un ampio dibattito sui diritti d’autore nell’era digitale.
Le aziende di spicco nel settore, tra cui Google e Meta, hanno dichiarato di utilizzare dati acquisiti legalmente, con Google che sottolinea l’uso di contenuti di YouTube secondo accordi con i creatori e Meta che vanta investimenti nell’intelligenza artificiale, utilizzando immagini e video da Instagram e Facebook.
Parallelamente, Google naviga in acque turbolente, confrontandosi con dilemmi legali riguardanti l’utilizzo dei dati di YouTube. Sebbene la politica interna di Google permetta l’uso dei dati per migliorare i servizi interni, rimane ambiguo se tali dati possano essere utilizzati per sviluppare servizi commerciali esterni.
In questo contesto, Google ha valutato l’espansione dell’utilizzo dei dati degli utenti, esplorando l’integrazione di informazioni da Google Docs e altre app nelle iniziative di IA.
Nel tentativo di superare la penuria di dati, Altman ha proposto un approccio pionieristico: addestrare l’IA su dati sintetici generati dall’intelligenza artificiale stessa. Questa metodologia potrebbe offrire una soluzione alla dipendenza da dati protetti da copyright, benché presenti sfide tecniche significative, come il rischio di feedback loop che possono rinforzare errori e limitazioni nei modelli di IA. |
| |
|
Limitare le fake news senza limitare la libertà di stampa |
| |
|
Il 2024 si preannuncia come un anno denso di elezioni nazionali in un numero record di paesi, sollevando preoccupazioni riguardo alla diffusione della disinformazione e alla disponibilità di notizie fondate per gli elettori.
Il Center for News, Technology & Innovation, un centro di ricerca politica globale indipendente, ha condotto uno studio sulle politiche riguardanti le false notizie attuate o proposte in 31 paesi nel periodo compreso tra il 2020 e il 2023.
Tale studio rivela che il testo di 32 atti legislativi offre scarso supporto alla tutela delle notizie basate sui fatti e, in molti casi, favorisce il controllo governativo sui media. La mancanza di garanzie in queste leggi rischia di limitare le libertà di stampa e giornalistiche in un anno elettorale cruciale.
Nello studio si evidenzia che, sebbene la legislazione possa svolgere un ruolo rilevante nella creazione di un ambiente digitale informativo che protegga sia la libertà di stampa che l’accesso del pubblico a notizie verificate, i legislatori dovrebbero essere consapevoli di tale complessità.
In generale, dall’analisi emerge un significativo aumento della legislazione contro le false notizie dopo la pandemia da COVID-19.
Come detto, molte di queste leggi, sembrano compromettere la protezione della stampa indipendente e potrebbero favorire il controllo governativo sulla diffusione delle informazioni, concedendo al governo l’autorità di determinare cosa costituisca una notizia falsa e aumentando il rischio di controllo dei media. Anche se le preoccupazioni sono più evidenti nei paesi autocratici, la mancanza di chiarezza si riscontra anche nelle democrazie. |
| |
|
La Cina con l’IA tenta di influenzare le elezioni americane |
| |
|
Non è una "voce di corridoio" ma il Microsoft Threat Analysis Center che venerdì scorso ha pubblicato un report che mette in evidenza gravi minacce informatiche provenienti dalla Cina e dalla Corea del Nord.
Microsoft accusa la Cina di voler interferire nelle prossime elezioni degli Stati Uniti, tramite la diffusione di contenuti generati dall’intelligenza artificiale sui social media, con l’obiettivo di influenzare l’elezione di candidati più vicini alle proprie posizioni.
Già In passato, la Cina aveva attuato questa strategia, tentando di influenzare le elezioni, a Taiwan a gennaio. Si ritiene che per quell’occasione il gruppo informatico cinese Storm 1376 avesse creato falsi account sui social media e pubblicato audio e video falsificati su YouTube per influenzare l’opinione pubblica. In quel caso YouTube intervenne prontamente rimuovendo il contenuto prima che potesse raggiungere un vasto pubblico.
Nel rapporto pubblicato da MTAC risulta evidente che gli Stati Uniti potrebbero essere il prossimo obiettivo di tali attacchi.
Dai dati emerge un aumento della creazione di falsi account sui social (account che sembrerebbero legati al governo cinese) che stanno ponendo domande provocatorie su questioni controverse come l’uso di droghe negli Stati Uniti, le politiche di immigrazione e le tensioni razziali. Tali post inoltre creati da un’intelligenza artificiale generativa chiedono ai follower di esprimere opinioni, presumibilmente per raccogliere informazioni sulle preferenze politiche degli elettori statunitensi e ciò potrebbe servire ad individuare con maggiore precisione i dati demografici dei principali gruppi di elettori in vista delle elezioni presidenziali statunitensi.
I tentativi di diffondere disinformazione includono la manipolazione dell’opinione pubblica riguardo eventi come il deragliamento del treno in Kentucky nel novembre 2023, gli incendi devastanti di Maui nell’agosto dello stesso anno, lo smaltimento delle acque reflue nucleari giapponesi e l’ampio dibattito sull’uso di droghe negli Stati Uniti.
Il Dipartimento di Stato americano ha sollevato preoccupazioni sulla possibilità che la Cina abbia intenzioni ostili e ha denunciato il finanziamento milionario delle autorità cinesi per promuovere la disinformazione online.
Ma finora, scrive Microsoft, non ci sono prove a sufficienza per affermare che questi sforzi siano riusciti a condizionare l’opinione pubblica americana. |
| |
|
Meta e OpenAI sono pronte per l'AGI (Artificial General Intelligence)? |
| |
|
Due delle più importanti aziende nel settore dell’intelligenza artificiale, OpenAI e Meta, rilasceranno a breve nuove versioni dei propri modelli, più evolute e potrebbero rappresentare una svolta significativa nella corsa verso le AGI (Artificial General Intelligence) ovvero quel livello di intelligenza artificiale che potrebbe essere in grado di ragionare e pianificare.
Durante un evento a Londra, tenutosi martedì, Nick Clegg presidente di Affari globali di Meta ha dichiarato: “Entro il prossimo mese, speriamo di iniziare a lanciare la nostra nuova suite di modelli di nuova generazione, Llama 3”.
Meta si prepara a rilasciare Llama 3 in diverse dimensioni di modello, proprio come aveva fatto con Llama 2, I modelli leggeri tendono ad attrarre gli utenti che non vogliono necessariamente utilizzare l’ampiezza di un modello linguistico di grandi dimensioni per le loro applicazioni ed inoltre possono essere utilizzati in progetti specifici come l’assistenza al codice o in dispositivi che non sono in grado di gestire il consumo di energia di un modello AI più grande, come telefoni o laptop.
L’intenzione è quella di lanciare due versioni ridotte di Llama 3 questo mese, prima del lancio del modello completo previsto per quest’estate.
Il responsabile ricerca sull’intelligenza artificiale di Meta Yann LeCun ha sottolineato che attualmente i sistemi di intelligenza artificiale “producono una parola dopo l’altra senza pensare e pianificare” e poiché hanno difficoltà a gestire questioni complesse o a conservare le informazioni per un lungo periodo, continuano a “commettere errori stupidi” ed ha quindi sottolineato la necessità di aggiungere il “ragionamento” a tali modelli descrivendo il ragionamento come un “grande pezzo mancante” per far progredire l’intelligenza artificiale.
Meta inoltre prevede di integrare il suo nuovo modello di intelligenza artificiale in WhatsApp e negli occhiali intelligenti Ray-Ban.
Chris Cox, direttore del prodotto di Meta, ha illustrato come le telecamere negli occhiali Ray-Ban potrebbero essere utilizzate per guardare, ad esempio, una macchina del caffè rotta, con un assistente di intelligenza artificiale alimentato da Llama 3 che spiegherebbe al portatore come ripararla.
Nel frattempo, OpenAI, supportata da Microsoft, ha annunciato il possibile arrivo di GPT-5, con l’obiettivo di far sì che anche i suoi modelli non solo parlino, ma che “ragionino” e pianifichino.
In un’intervista rilasciata al Financial Times Il direttore operativo di OpenAI, Brad Lightcap, ha dichiarato che la prossima generazione di GPT mostrerà progressi nella risoluzione di “problemi difficili” come il ragionamento.
“Inizieremo a vedere l’intelligenza artificiale in grado di svolgere compiti più complessi in modo più sofisticato”, ha affermato ritiene infatti che i compiti affidati all’IA sono ancora troppo limitati rispetto alle capacità che possono effettivamente offrire.
Il “ragionamento” e la pianificazione sono considerati passaggi fondamentali verso ciò che i ricercatori di intelligenza artificiale chiamano “Intelligenza Generale Artificiale”, permettendo ai chatbot e agli assistenti virtuali di completare sequenze di compiti correlati e prevedere le conseguenze delle loro azioni.
Lightcap ha aggiunto che OpenAI avrà “qualcosa di più da dire presto” sulla prossima versione di GPT, sottolineando il futuro potenziale per affrontare compiti più complessi e migliorare la capacità di ragionamento dei modelli.
Nel frattempo, durante un’intervista su X, Elon Musk ha dichiarato: “La mia ipotesi è che avremo un’IA più intelligente di qualsiasi umano probabilmente entro la fine del prossimo anno”, riflettendo sull’evoluzione dei modelli attuali probabilmente non bisognerà neanche aspettare il prossimo anno per ottenere questo risultato.
In ultimo ci poniamo solo una domanda: cosa mai si intenderà per “ragionamento” di questi sistemi? |
| |
|
Corso wordpress per giornalisti accreditato OdG: 10 cfp |
| |
|
Sempre gratuita e disponibile |
Lavoriamo tanto per realizzare la nostra newsletter SØØn e ne siamo orgogliosi.
Sarà sempre gratuita e disponibile in archivio sul nostro sito.
Aiutaci, condividila con i tuoi contatti. |
|
|
| |
|